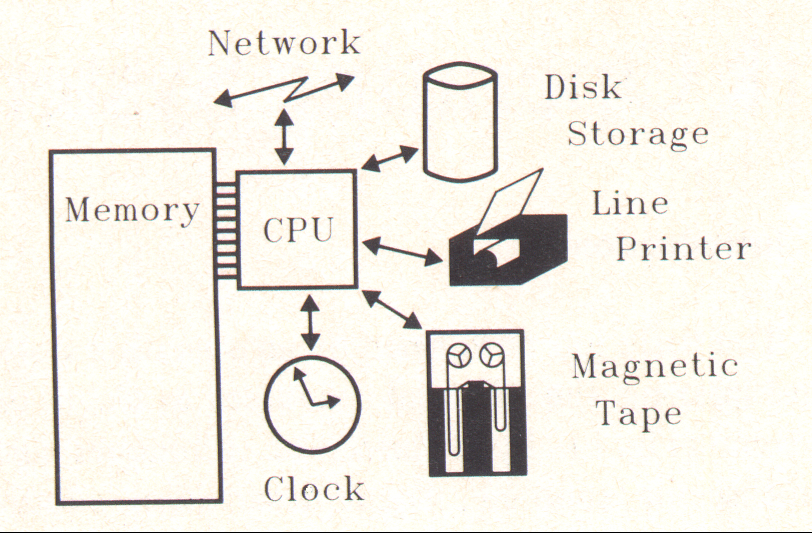
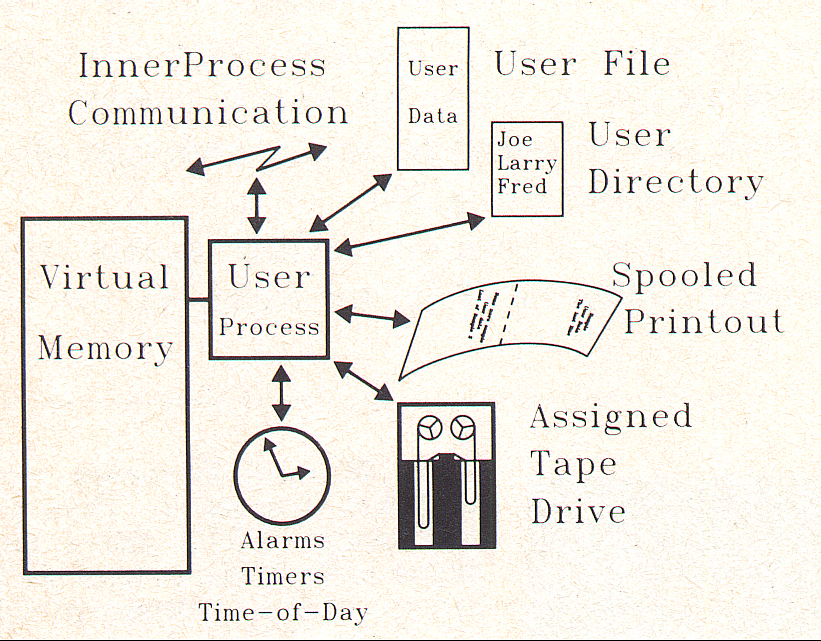
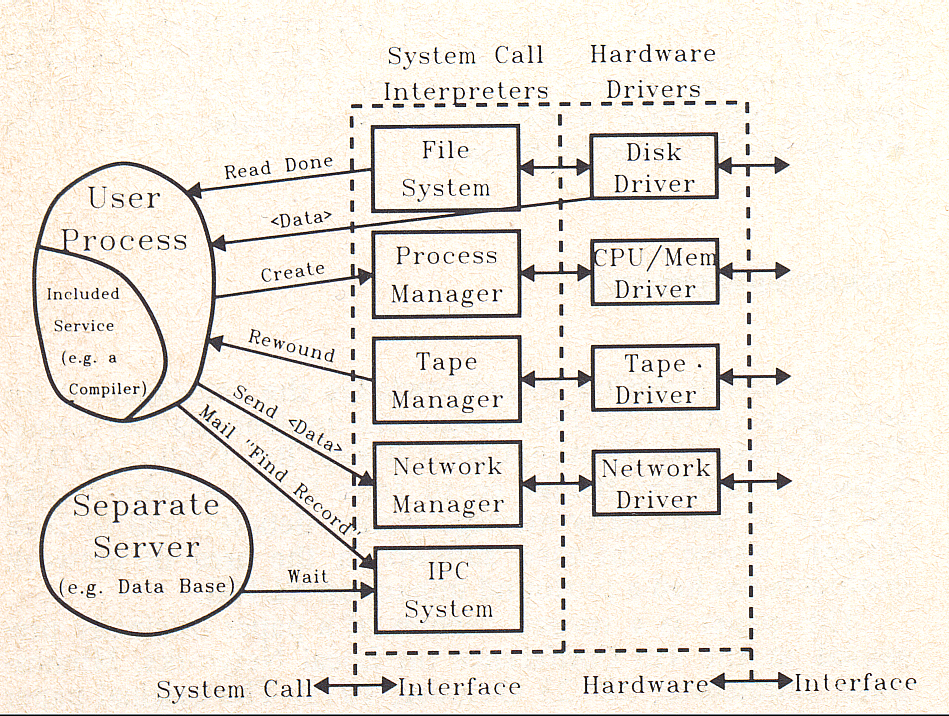
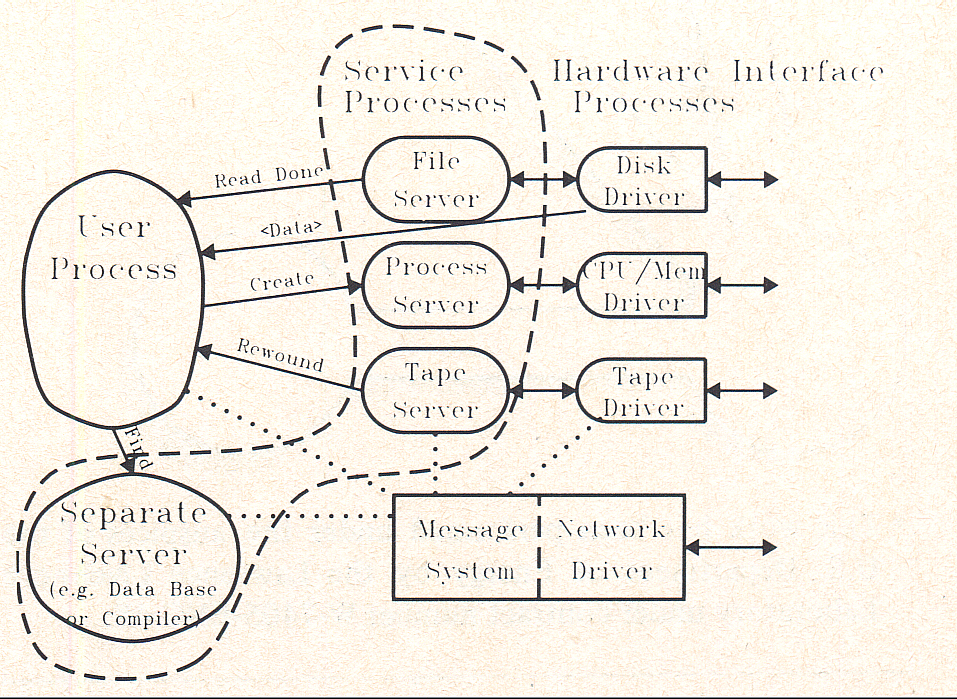
Step-by-Step Guide to Installing Cluster Service
This step-by-step guide provides instructions for installing Cluster service on servers running the Windows® 2000 Advanced Server and Windows 2000 Datacenter Server operating systems. The guide describes the process of installing the Cluster service on cluster nodes. It is not intended to explain how to install cluster applications. Rather, it guides you through the process of installing a typical, two-node cluster itself.
On This Page
Introduction
Checklists for Cluster Server Installation
Cluster Installation
Install Cluster Service software
Verify Installation
For Additional Information
Appendix A
Introduction
A server cluster is a group of independent servers running Cluster service and working collectively as a single system. Server clusters provide high-availability, scalability, and manageability for resources and applications by grouping multiple servers running Windows® 2000 Advanced Server or Windows 2000 Datacenter Server.
The purpose of server clusters is to preserve client access to applications and resources during failures and planned outages. If one of the servers in the cluster is unavailable due to failure or maintenance, resources and applications move to another available cluster node.
For clustered systems, the term high availability is used rather than fault-tolerant, as fault tolerant technology offers a higher level of resilience and recovery. Fault-tolerant servers typically use a high degree of hardware redundancy plus specialized software to provide near-instantaneous recovery from any single hardware or software fault. These solutions cost significantly more than a clustering solution because organizations must pay for redundant hardware that waits idly for a fault. Fault-tolerant servers are used for applications that support high-value, high-rate transactions such as check clearinghouses, Automated Teller Machines (ATMs), or stock exchanges.
While Cluster service does not guarantee non-stop operation, it provides availability sufficient for most mission-critical applications. Cluster service can monitor applications and resources, automatically recognizing and recovering from many failure conditions. This provides greater flexibility in managing the workload within a cluster, and improves overall availability of the system.
Cluster service benefits include:
· High Availability. With Cluster service, ownership of resources such as disk drives and IP addresses is automatically transferred from a failed server to a surviving server. When a system or application in the cluster fails, the cluster software restarts the failed application on a surviving server, or disperses the work from the failed node to the remaining nodes. As a result, users experience only a momentary pause in service.
· Failback. Cluster service automatically re-balances the workload in a cluster when a failed server comes back online.
· Manageability. You can use the Cluster Administrator to manage a cluster as a single system and to manage applications as if they were running on a single server. You can move applications to different servers within the cluster by dragging and dropping cluster objects. You can move data to different servers in the same way. This can be used to manually balance server workloads and to unload servers for planned maintenance. You can also monitor the status of the cluster, all nodes and resources from anywhere on the network.
· Scalability. Cluster services can grow to meet rising demands. When the overall load for a cluster-aware application exceeds the capabilities of the cluster, additional nodes can be added.
This paper provides instructions for installing Cluster service on servers running Windows 2000 Advanced Server and Windows 2000 Datacenter Server. It describes the process of installing the Cluster service on cluster nodes. It is not intended to explain how to install cluster applications, but rather to guide you through the process of installing a typical, two-node cluster itself.
Top of page
Checklists for Cluster Server Installation
This checklist assists you in preparing for installation. Step-by-step instructions begin after the checklist.
Software Requirements
· Microsoft Windows 2000 Advanced Server or Windows 2000 Datacenter Server installed on all computers in the cluster.
· A name resolution method such as Domain Naming System (DNS), Windows Internet Naming System (WINS), HOSTS, etc.
· Terminal Server to allow remote cluster administration is recommended.
Hardware Requirements
· The hardware for a Cluster service node must meet the hardware requirements for Windows 2000 Advanced Server or Windows 2000 Datacenter Server. These requirements can be found at The Product Compatibility Search page
· Cluster hardware must be on the Cluster Service Hardware Compatibility List (HCL). The latest version of the Cluster Service HCL can be found by going to the Windows Hardware Compatibility List and then searching on Cluster.
Two HCL-approved computers, each with the following:
o A boot disk with Windows 2000 Advanced Server or Windows 2000 Datacenter Server installed. The boot disk cannot be on the shared storage bus described below.
o A separate PCI storage host adapter (SCSI or Fibre Channel) for the shared disks. This is in addition to the boot disk adapter.
o Two PCI network adapters on each machine in the cluster.
o An HCL-approved external disk storage unit that connects to all computers. This will be used as the clustered disk. A redundant array of independent disks (RAID) is recommended.
o Storage cables to attach the shared storage device to all computers. Refer to the manufacturers' instructions for configuring storage devices. If an SCSI bus is used, see Appendix A for additional information.
o All hardware should be identical, slot for slot, card for card, for all nodes. This will make configuration easier and eliminate potential compatibility problems.
Network Requirements
· A unique NetBIOS cluster name.
· Five unique, static IP addresses: two for the network adapters on the private network, two for the network adapters on the public network, and one for the cluster itself.
· A domain user account for Cluster service (all nodes must be members of the same domain).
· Each node should have two network adapters—one for connection to the public network and the other for the node-to-node private cluster network. If you use only one network adapter for both connections, your configuration is unsupported. A separate private network adapter is required for HCL certification.
Shared Disk Requirements:
· All shared disks, including the quorum disk, must be physically attached to a shared bus.
· Verify that disks attached to the shared bus can be seen from all nodes. This can be checked at the host adapter setup level. Please refer to the manufacturer's documentation for adapter-specific instructions.
· SCSI devices must be assigned unique SCSI identification numbers and properly terminated, as per manufacturer's instructions.
· All shared disks must be configured as basic (not dynamic).
· All partitions on the disks must be formatted as NTFS.
While not required, the use of fault-tolerant RAID configurations is strongly recommended for all disks. The key concept here is fault-tolerant raid configurations—not stripe sets without parity.
Top of page
Cluster Installation
Installation Overview
During the installation process, some nodes will be shut down and some nodes will be rebooted. These steps are necessary to guarantee that the data on disks that are attached to the shared storage bus is not lost or corrupted. This can happen when multiple nodes try to simultaneously write to the same disk that is not yet protected by the cluster software.
Use Table 1 below to determine which nodes and storage devices should be powered on during each step.
The steps in this guide are for a two-node cluster. However, if you are installing a cluster with more than two nodes, you can use the Node 2 column to determine the required state of other nodes.
Table 1 Power Sequencing Table for Cluster Installation
| Step | Node 1 | Node 2 | Storage | Comments |
| Setting Up Networks | On | On | Off | Verify that all storage devices on the shared bus are powered off. Power on all nodes. |
| Setting up Shared Disks | On | Off | On | Shutdown all nodes. Power on the shared storage, then power on the first node. |
| Verifying Disk Configuration | Off | On | On | Shut down first node, power on second node. Repeat for nodes 3 and 4 if necessary. |
| Configuring the First Node | On | Off | On | Shutdown all nodes; power on the first node. |
| Configuring the Second Node | On | On | On | Power on the second node after the first node was successfully configured. Repeat for nodes 3 and 4 if necessary. |
| Post-installation | On | On | On | At this point all nodes should be on. |
Several steps must be taken prior to the installation of the Cluster service software. These steps are:
· Installing Windows 2000 Advanced Server or Windows 2000 Datacenter Server on each node.
· Setting up networks.
· Setting up disks.
Perform these steps on every cluster node before proceeding with the installation of Cluster service on the first node.
To configure the Cluster service on a Windows 2000-based server, your account must have administrative permissions on each node. All nodes must be member servers, or all nodes must be domain controllers within the same domain. It is not acceptable to have a mix of domain controllers and member servers in a cluster.
Installing the Windows 2000 Operating System
Please refer to the documentation you received with the Windows 2000 operating system packages to install the system on each node in the cluster.
This step-by-step guide uses the naming structure from the "Step-by-Step Guide to a Common Infrastructure for Windows 2000 Server Deployment" http://www.microsoft.com/windows2000/techinfo/planning/server/serversteps.asp. However, you can use any names.
You must be logged on as an administrator prior to installation of Cluster service.
Setting up Networks
Note: For this section, power down all shared storage devices and then power up all nodes. Do not let both nodes access the shared storage devices at the same time until the Cluster service is installed on at least one node and that node is online.
Each cluster node requires at least two network adapters—one to connect to a public network, and one to connect to a private network consisting of cluster nodes only.
The private network adapter establishes node-to-node communication, cluster status signals, and cluster management. Each node's public network adapter connects the cluster to the public network where clients reside.
Verify that all network connections are correct, with private network adapters connected to other private network adapters only, and public network adapters connected to the public network. The connections are illustrated in Figure 1 below. Run these steps on each cluster node before proceeding with shared disk setup.

Figure 1: Example of two-node cluster (clusterpic.vsd)
Configuring the Private Network Adapter
Perform these steps on the first node in your cluster.
1. Right-click My Network Places and then click Properties.
2. Right-click the Local Area Connection 2 icon.
Note: Which network adapter is private and which is public depends upon your wiring. For the purposes of this document, the first network adapter (Local Area Connection) is connected to the public network, and the second network adapter (Local Area Connection 2) is connected to the private cluster network. This may not be the case in your network.
3. Click Status. The Local Area Connection 2 Status window shows the connection status, as well as the speed of connection. If the window shows that the network is disconnected, examine cables and connections to resolve the problem before proceeding. Click Close.
4. Right-click Local Area Connection 2 again, click Properties, and click Configure.
5. Click Advanced. The window in Figure 2 should appear.
6. Network adapters on the private network should be set to the actual speed of the network, rather than the default automated speed selection. Select your network speed from the drop-down list. Do not use an Auto-select setting for speed. Some adapters may drop packets while determining the speed. To set the network adapter speed, click the appropriate option such as Media Type or Speed.

Figure 2: Advanced Adapter Configuration (advanced.bmp)
All network adapters in the cluster that are attached to the same network must be identically configured to use the same Duplex Mode, Flow Control, Media Type, and so on. These settings should remain the same even if the hardware is different.
Note: We highly recommend that you use identical network adapters throughout the cluster network.
7. Click Transmission Control Protocol/Internet Protocol (TCP/IP).
8. Click Properties.
9. Click the radio-button for Use the following IP address and type in the following address: 10.1.1.1. (Use 10.1.1.2 for the second node.)
10. Type in a subnet mask of 255.0.0.0.
11. Click the Advanced radio button and select the WINS tab. Select Disable NetBIOS over TCP/IP. Click OK to return to the previous menu. Do this step for the private network adapter only.
The window should now look like Figure 3 below.

Figure 3: Private Connector IP Address (ip10111.bmp)
Configuring the Public Network Adapter
Note: While the public network adapter's IP address can be automatically obtained if a DHCP server is available, this is not recommended for cluster nodes. We strongly recommend setting static IP addresses for all network adapters in the cluster, both private and public. If IP addresses are obtained via DHCP, access to cluster nodes could become unavailable if the DHCP server goes down. If you must use DHCP for your public network adapter, use long lease periods to assure that the dynamically assigned lease address remains valid even if the DHCP service is temporarily lost. In all cases, set static IP addresses for the private network connector. Keep in mind that Cluster service will recognize only one network interface per subnet. If you need assistance with TCP/IP addressing in Windows 2000, please see Windows 2000 Online Help.
Rename the Local Area Network Icons
We recommend changing the names of the network connections for clarity. For example, you might want to change the name of Local Area Connection (2) to something like Private Cluster Connection. The naming will help you identify a network and correctly assign its role.
1. Right-click the Local Area Connection 2 icon.
2. Click Rename.
3. Type Private Cluster Connection into the textbox and press Enter.
4. Repeat steps 1-3 and rename the public network adapter as Public Cluster Connection.

Figure 4: Renamed connections (connames.bmp)
5. The renamed icons should look like those in Figure 4 above. Close the Networking and Dial-up Connections window. The new connection names automatically replicate to other cluster servers as they are brought online.
Verifying Connectivity and Name Resolution
To verify that the private and public networks are communicating properly, perform the following steps for each network adapter in each node. You need to know the IP address for each network adapter in the cluster. If you do not already have this information, you can retrieve it using the ipconfig command on each node:
1. Click Start, click Run and type cmd in the text box. Click OK.
2. Type ipconfig /all and press Enter. IP information should display for all network adapters in the machine.
3. If you do not already have the command prompt on your screen, click Start, click Run and typing cmd in the text box. Click OK.
4. Type ping ipaddress where ipaddress is the IP address for the corresponding network adapter in the other node. For example, assume that the IP addresses are set as follows:
| Node | Network Name | Network Adapter IP Address |
| 1 | Public Cluster Connection | 172.16.12.12. |
| 1 | Private Cluster Connection | 10.1.1.1 |
| 2 | Public Cluster Connection | 172.16.12.14 |
| 2 | Private Cluster Connection | 10.1.1.2 |
In this example, you would type ping 172.16.12.14 and ping 10.1.1.2 from Node 1, and you would type ping 172.16.12.12 and 10.1.1.1 from Node 2.
To verify name resolution, ping each node from a client using the node's machine name instead of its IP number. For example, to verify name resolution for the first cluster node, type ping hq-res-dc01 from any client.
Verifying Domain Membership
All nodes in the cluster must be members of the same domain and able to access a domain controller and a DNS Server. They can be configured as member servers or domain controllers. If you decide to configure one node as a domain controller, you should configure all other nodes as domain controllers in the same domain as well. In this document, all nodes are configured as domain controllers.
Note: See More Information at the end of this document for links to additional Windows 2000 documentation that will help you understand and configure domain controllers, DNS, and DHCP.
1. Right-click My Computer, and click Properties.
2. Click Network Identification. The System Properties dialog box displays the full computer name and domain. In our example, the domain name is reskit.com.
3. If you are using member servers and need to join a domain, you can do so at this time. Click Properties and following the on-screen instructions for joining a domain.
4. Close the System Properties and My Computer windows.
Setting Up a Cluster User Account
The Cluster service requires a domain user account under which the Cluster service can run. This user account must be created before installing Cluster service, because setup requires a user name and password. This user account should not belong to a user on the domain.
1. Click Start, point to Programs, point to Administrative Tools, and click Active Directory Users and Computers
2. Click the + to expand Reskit.com (if it is not already expanded).
3. Click Users.
4. Right-click Users, point to New, and click User.
5. Type in the cluster name as shown in Figure 5 below and click Next.

Figure 5: Add Cluster User (clusteruser.bmp)
6. Set the password settings to User Cannot Change Password and Password Never Expires. Click Next and then click Finish to create this user.
Note: If your administrative security policy does not allow the use of passwords that never expire, you must renew the password and update the cluster service configuration on each node before password expiration.
7. Right-click Cluster in the left pane of the Active Directory Users and Computers snap-in. Select Properties from the context menu.
8. Click Add Members to a Group.
9. Click Administrators and click OK. This gives the new user account administrative privileges on this computer.
10. Close the Active Directory Users and Computers snap-in.
Setting Up Shared Disks
Warning: Make sure that Windows 2000 Advanced Server or Windows 2000 Datacenter Server and the Cluster service are installed and running on one node before starting an operating system on another node. If the operating system is started on other nodes before the Cluster service is installed, configured and running on at least one node, the cluster disks will probably be corrupted.
To proceed, power off all nodes. Power up the shared storage devices and then power up node one.
About the Quorum Disk
The quorum disk is used to store cluster configuration database checkpoints and log files that help manage the cluster. We make the following quorum disk recommendations:
· Create a small partition (min 50MB) to be used as a quorum disk. We generally recommend a quorum disk to be 500MB.)
· Dedicate a separate disk for a quorum resource. As the failure of the quorum disk would cause the entire cluster to fail, we strongly recommend you use a volume on a RAID disk array.
During the Cluster service installation, you must provide the drive letter for the quorum disk. In our example, we use the letter Q.
Configuring Shared Disks
1. Right click My Computer, click Manage, and click Storage.
2. Double-click Disk Management
3. Verify that all shared disks are formatted as NTFS and are designated as Basic. If you connect a new drive, the Write Signature and Upgrade Disk Wizard starts automatically. If this happens, click Next to go through the wizard. The wizard sets the disk to dynamic. To reset the disk to Basic, right-click Disk # (where # specifies the disk you are working with) and click Revert to Basic Disk.
Right-click unallocated disk space
1. Click Create Partition…
2. The Create Partition Wizard begins. Click Next twice.
3. Enter the desired partition size in MB and click Next.
4. Accept the default drive letter assignment by clicking Next.
5. Click Next to format and create partition.
Assigning Drive Letters
After the bus, disks, and partitions have been configured, drive letters must be assigned to each partition on each clustered disk.
Note: Mountpoints is a feature of the file system that allows you to mount a file system using an existing directory without assigning a drive letter. Mountpoints is not supported on clusters. Any external disk used as a cluster resource must be partitioned using NTFS partitions and must have a drive letter assigned to it.
1. Right-click the desired partition and select Change Drive Letter and Path.
2. Select a new drive letter.
3. Repeat steps 1 and 2 for each shared disk.

Figure 6: Disks with Drive Letters Assigned (drives.bmp)
4. When finished, the Computer Management window should look like Figure 6 above. Now close the Computer Management window.
Verifying Disk Access and Functionality
1. Click Start, click Programs, click Accessories, and click Notepad.
2. Type some words into Notepad and use the File/Save As command to save it as a test file called test.txt. Close Notepad.
3. Double-click the My Documents icon.
4. Right-click test.txt and click Copy
5. Close the window.
6. Double-click My Computer.
7. Double-click a shared drive partition.
8. Click Edit and click Paste.
9. A copy of the file should now reside on the shared disk.
10. Double-click test.txt to open it on the shared disk. Close the file.
11. Highlight the file and press the Del key to delete it from the clustered disk.
Repeat the process for all clustered disks to verify they can be accessed from the first node.
At this time, shut down the first node, power on the second node and repeat the Verifying Disk Access and Functionality steps above. Repeat again for any additional nodes. When you have verified that all nodes can read and write from the disks, turn off all nodes except the first, and continue with this guide.
Top of page
Install Cluster Service software
Configuring the First Node
Note: During installation of Cluster service on the first node, all other nodes must either be turned off, or stopped prior to Windows 2000 booting. All shared storage devices should be powered up.
In the first phase of installation, all initial cluster configuration information must be supplied so that the cluster can be created. This is accomplished using the Cluster Service Configuration Wizard.
1. Click Start, click Settings, and click Control Panel.
2. Double-click Add/Remove Programs.
3. Double-click Add/Remove Windows Components .
4. Select Cluster Service. Click Next.
5. Cluster service files are located on the Windows 2000 Advanced Server or Windows 2000 Datacenter Server CD-ROM. Enter x:\i386 (where x is the drive letter of your CD-ROM). If Windows 2000 was installed from a network, enter the appropriate network path instead. (If the Windows 2000 Setup flashscreen displays, close it.) Click OK.
6. Click Next.
7. The window shown in Figure 7 below appears. Click I Understand to accept the condition that Cluster service is supported on hardware from the Hardware Compatibility List only.

Figure 7: Hardware Configuration Certification Screen (hcl.bmp)
8. Because this is the first node in the cluster, you must create the cluster itself. Select The first node in the cluster, as shown in Figure 8 below and then click Next.

Figure 8: Create New Cluster (clustcreate.bmp)
9. Enter a name for the cluster (up to 15 characters), and click Next. (In our example, we name the cluster MyCluster.)
10. Type the user name of the cluster service account that was created during the pre-installation. (In our example, this user name is cluster.) Leave the password blank. Type the domain name, and click Next.
Note: You would normally provide a secure password for this user account.
At this point the Cluster Service Configuration Wizard validates the user account and password.
11. Click Next.
Configuring Cluster Disks
Note: By default, all SCSI disks not residing on the same bus as the system disk will appear in the Managed Disks list. Therefore, if the node has multiple SCSI buses, some disks may be listed that are not to be used as shared storage (for example, an internal SCSI drive.) Such disks should be removed from the Managed Disks list.
1. The Add or Remove Managed Disks dialog box shown in Figure 9 specifies which disks on the shared SCSI bus will be used by Cluster service. Add or remove disks as necessary and then click Next.

Figure 9: Add or Remove Managed Disks (manageddisks.bmp)
Note that because logical drives F: and G: exist on a single hard disk, they are seen by Cluster service as a single resource. The first partition of the first disk is selected as the quorum resource by default. Change this to denote the small partition that was created as the quorum disk (in our example, drive Q). Click Next.
Note: In production clustering scenarios you must use more than one private network for cluster communication to avoid having a single point of failure. Cluster service can use private networks for cluster status signals and cluster management. This provides more security than using a public network for these roles. You can also use a public network for cluster management, or you can use a mixed network for both private and public communications. In any case, make sure at least two networks are used for cluster communication, as using a single network for node-to-node communication represents a potential single point of failure. We recommend that multiple networks be used, with at least one network configured as a private link between nodes and other connections through a public network. If you have more than one private network, make sure that each uses a different subnet, as Cluster service recognizes only one network interface per subnet.
This document is built on the assumption that only two networks are in use. It shows you how to configure these networks as one mixed and one private network.
The order in which the Cluster Service Configuration Wizard presents these networks may vary. In this example, the public network is presented first.
2. Click Next in the Configuring Cluster Networks dialog box.
3. Make sure that the network name and IP address correspond to the network interface for the public network.
4. Check the box Enable this network for cluster use.
5. Select the option All communications (mixed network) as shown in Figure 10 below.
6. Click Next.

Figure 10: Public Network Connection (pubclustnet.bmp)
7. The next dialog box shown in Figure 11 configures the private network. Make sure that the network name and IP address correspond to the network interface used for the private network.
8. Check the box Enable this network for cluster use.
9. Select the option Internal cluster communications only.

Figure 11: Private Network Connection (privclustnet.bmp)
10. Click Next.
11. In this example, both networks are configured in such a way that both can be used for internal cluster communication. The next dialog window offers an option to modify the order in which the networks are used. Because Private Cluster Connection represents a direct connection between nodes, it is left at the top of the list. In normal operation this connection will be used for cluster communication. In case of the Private Cluster Connection failure, cluster service will automatically switch to the next network on the list—in this case Public Cluster Connection. Make sure the first connection in the list is the Private Cluster Connection and click Next.
Important: Always set the order of the connections so that the Private Cluster Connection is first in the list.
12. Enter the unique cluster IP address (172.16.12.20) and Subnet mask (255.255.252.0), and click Next.

Figure 12: Cluster IP Address (clusterip.bmp)
The Cluster Service Configuration Wizard shown in Figure 12 automatically associates the cluster IP address with one of the public or mixed networks. It uses the subnet mask to select the correct network.
13. Click Finish to complete the cluster configuration on the first node.
The Cluster Service Setup Wizard completes the setup process for the first node by copying the files needed to complete the installation of Cluster service. After the files are copied, the Cluster service registry entries are created, the log files on the quorum resource are created, and the Cluster service is started on the first node.
A dialog box appears telling you that Cluster service has started successfully.
14. Click OK.
15. Close the Add/Remove Programs window.
Validating the Cluster Installation
Use the Cluster Administrator snap-in to validate the Cluster service installation on the first node.
1. Click Start, click Programs, click Administrative Tools, and click Cluster Administrator.

Figure 13: Cluster Administrator (1nodeadmin.bmp)
If your snap-in window is similar to that shown above in Figure 13, your Cluster service was successfully installed on the first node. You are now ready to install Cluster service on the second node.
Configuring the Second Node
Note: For this section, leave node one and all shared disks powered on. Power up the second node.
Installing Cluster service on the second node requires less time than on the first node. Setup configures the Cluster service network settings on the second node based on the configuration of the first node.
Installation of Cluster service on the second node begins exactly as for the first node. During installation of the second node, the first node must be running.
Follow the same procedures used for installing Cluster service on the first node, with the following differences:
1. In the Create or Join a Cluster dialog box, select The second or next node in the cluster, and click Next.
2. Enter the cluster name that was previously created (in this example, MyCluster), and click Next.
3. Leave Connect to cluster as unchecked. The Cluster Service Configuration Wizard will automatically supply the name of the user account selected during the installation of the first node. Always use the same account used when setting up the first cluster node.
4. Enter the password for the account (if there is one) and click Next.
5. At the next dialog box, click Finish to complete configuration.
6. The Cluster service will start. Click OK.
7. Close Add/Remove Programs.
If you are installing additional nodes, repeat these steps to install Cluster service on all other nodes.
Top of page
Verify Installation
There are several ways to verify a successful installation of Cluster service. Here is a simple one:
1. Click Start, click Programs, click Administrative Tools, and click Cluster Administrator.

Figure 14: Cluster Resources (clustadmin.bmp)
The presence of two nodes (HQ-RES-DC01 and HQ-RES-DC02 in Figure 14 above) shows that a cluster exists and is in operation.
2. Right Click the group Disk Group 1 and select the option Move. The group and all its resources will be moved to another node. After a short period of time the Disk F: G: will be brought online on the second node. If you watch the screen, you will see this shift. Close the Cluster Administrator snap-in.
Congratulations. You have completed the installation of Cluster service on all nodes. The server cluster is fully operational. You are now ready to install cluster resources like file shares, printer spoolers, cluster aware services like IIS, Message Queuing, Distributed Transaction Coordinator, DHCP, WINS, or cluster aware applications like Exchange or SQL Server.
Top of page
For Additional Information
This guide covers a simple installation of Cluster service. For more articles and papers on Windows 2000 Server, Windows 2000 Advanced Server, and Windows 2000 Cluster service, see: The Windows 2000 Web site. For information on installing DHCP, Active Directory, and other services, see Windows 2000 Online Help, the Windows 2000 Planning and Deployment Guide, and the Windows 2000 Resource Kit.
Top of page
Appendix A
This appendix is provided as a generic instruction set for SCSI drive installations. If the SCSI hard disk vendor's instructions conflict with the instructions here, always use the instructions supplied by the vendor".
The SCSI bus listed in the hardware requirements must be configured prior to installation of Cluster services. This includes:
· Configuring the SCSI devices.
· Configuring the SCSI controllers and hard disks to work properly on a shared SCSI bus.
· Properly terminating the bus. The shared SCSI bus must have a terminator at each end of the bus. It is possible to have multiple shared SCSI buses between the nodes of a cluster.
In addition to the information on the following pages, refer to the documentation from the manufacturer of the SCSI device or the SCSI specifications, which can be ordered from the American National Standards Institute (ANSI). The ANSI web site contains a catalog that can be searched for the SCSI specifications.
Configuring the SCSI Devices
Each device on the shared SCSI bus must have a unique SCSI ID. Since most SCSI controllers default to SCSI ID 7, part of configuring the shared SCSI bus will be to change the SCSI ID on one controller to a different SCSI ID, such as SCSI ID 6. If there is more than one disk that will be on the shared SCSI bus, each disk must also have a unique SCSI ID.
Some SCSI controllers reset the SCSI bus when they initialize at boot time. If this occurs, the bus reset can interrupt any data transfers between the other node and disks on the shared SCSI bus. Therefore, SCSI bus resets should be disabled if possible.
Terminating the Shared SCSI Bus
Y cables can be connected to devices if the device is at the end of the SCSI bus. A terminator can then be attached to one branch of the Y cable to terminate the SCSI bus. This method of termination requires either disabling or removing any internal terminators the device may have.
Trilink connectors can be connected to certain devices. If the device is at the end of the bus, a trilink connector can be used to terminate the bus. This method of termination requires either disabling or removing any internal terminators the device may have.
Y cables and trilink connectors are the recommended termination methods, because they provide termination even when one node is not
Step-by-Step Guide to Software Installation and Maintenance
Software Installation and Maintenance for the Windows® 2000 operating system allows administrators to manage software for their organizations, including applications, service packs, and operating system upgrades. This overview guide explains how to use the Software Installation extension of the Group Policy Microsoft Management Console snap-in to specify policy settings for application deployment for groups of users and computers.
On This Page
Introduction
Prerequisites and Initial Configuration
Software Installation Snap-in CONFIGURATION
Software Installation and Maintenance Scenarios
Appendix – An Excel 97 .Zap File
Related Links
Introduction
This document is part of a set of step-by-step guides that introduce the Change and Configuration Management features of the Windows® 2000 operating system. This guide presents an overview of Software Installation and Maintenance. It also explains how to use the Software Installation extension of the Group Policy Microsoft Management Console snap-in to specify policy settings for application deployment for groups of users and computers.
Software Installation and Maintenance is dependent upon both the Active Directory and Group Policy. Administrators who are responsible for Software Installation and Maintenance should be familiar with both of these technologies.
Publish vs. Assign
Administrators can use Software Installation and Maintenance to either publish or assign software:
· Publish. Administrators publish applications that users may find useful, allowing users to decide whether to install the application. You can only publish to users, not computers.
· Assign. Administrators assign applications that users require to perform their jobs. Assigned applications are available on users' desktops automatically.
For a comparison of these capabilities, see Table 1 below. Administrators deploy applications in Group Policy objects (GPOs) that are associated with Active Directory containers such as sites, domains, and organizational units (OUs).
Table 1 Publishing and Assigning Software
| | Publish to Users | Assign to Users | Assign to Computers |
| After the administrator deploys the software, it is available for installation: | If an application is deployed in a GPO that is already applied to the user from a previous logon, it is available for installation in the current logon session (from the Add/Remove Programs Control Panel). If the application is deployed in a new GPO that is not already associated with the user, then it is available at the next logon. | If an application is deployed in a GPO that is already applied to the user from a previous logon, it is available for installation in the current logon session (from the Add/Remove Programs Control Panel). If the application is deployed in a new GPO that is not already associated with the user, then it is available at the next logon. | The next time the computer starts (reboot). |
| Typically, users install the software from: | The Add/Remove Programs in Control Panel. | Start menu shortcut.
Desktop shortcut.
Add/Remove Programs in Control Panel. | The software is already installed. |
| If the software is not installed and the user opens a file associated with the software, will the application install? | Yes. | Yes. | The software is already installed. |
| Can the users remove the software using the Add/Remove Programs in Control Panel? | Yes. Users can re-install the application from the Add/Remove Programs in Control Panel. | Yes. The software will be re-advertised immediately. This means that the shortcuts will be present in the users' desktops and they can re-install the application by clicking on a shortcut, for example. | No. Only the local administrator can remove the software. A user can run a repair on the software. |
| Supported installation file types: | Windows Installer packages (.msi files), and ZAP files. | Windows Installer packages (.msi files) | Windows Installer packages (.msi files) |
Supported Installation File Types
Software Installation and Maintenance supports Windows Installer packages (.msi files), repackaged files, and .zap files.
A Windows Installer package (.msi file) contains all the information necessary to describe to the Windows Installer how to set up an application. It covers every conceivable situation: various platforms, different sets of previously installed products, earlier versions of a product, and numerous default installation locations. Some applications such as Office 2000 provide their own .msi files. These are referred to as natively-authored Windows Installer packages.
You can create Windows Installer packages for your applications by using package-authoring tools provided by various vendors such as InstallShield Software Corporation and WISE Solutions, Inc. See the section on Windows Installer Applications for more information.
You can also repackage an existing application for use with the Windows Installer. To create a package for the application, you use a repackaging tool such as the VERITAS WinInstall LE, described later in this document.
Non-Windows Installer-based applications must use a .zap file to describe their existing setup program. A .zap file is a text file (similar to .ini files) that provides information about how to install a program, the application properties, and the entry points that the application should install. A sample .zap file is included in the appendix - An Excel 97 .Zap File.
Top of page
Prerequisites and Initial Configuration
Prerequisites
This Software Installation and Maintenance document is based on the two-part, "Step-by-Step Guide to a Common Infrastructure for Windows 2000 Server Deployment" http://www.microsoft.com/windows2000/techinfo/planning/server/serversteps.asp
Before beginning the steps in this guide, you need to build the common infrastructure, which specifies a particular hardware and software configuration. If you are not using the common infrastructure, you need to make the appropriate changes to this guide.
Software Installation and Maintenance is dependent on Group Policy. It is highly recommended that you complete the Group Policy step-by-step guide before the Software Installation and Maintenance guide.
Note: If you completed the Group Policy guide, it may be necessary to disable some of the policies particularly the loopback policies, as they may not allow people to install software from the Add/Remove Programs in the Control Panel.
Additionally, you may want to use the "Step-by-Step Guide toRepackaging Software for the Windows Installer Using VERITAS WinINSTALL LE "and repackage some software before you continue with this guide.
Windows Installer Applications
Software Installation and Maintenance leverages the new Windows Installer service that is a part of the Windows family of operating systems. (The Windows Installer is available in Windows 2000, Windows NT 4.0, Windows 98 and Windows 95.)For the best performance and the greatest reduction in TCO, you need to use applications that support the Windows Installer.
No sample applications are supplied for these guides. You must acquire applications such as Microsoft Office 2000 that supply a natively authored Windows Installer package (an .msi file). Or you must use an authoring or repackaging tool to create Windows Installer packages for your software.
You can author a Windows Installer package using a package-authoring tool if you have all of the files and know the architecture of the application. Package authoring tools are available from the following vendors:
· InstallShield Software Corporation. Information is available at the InstallShield Web site http://www.installshield.com.
· WISE Solutions, Inc. For information, see the WISE Solutions Web site http://www.wisesolutions.com.
If you want to use Software Installation and Maintenance with an existing application, you may want to consider repackaging the application to support the Windows Installer. The VERITAS WinInstall LE for repackaging of existing applications for use by the Windows Installer is available on the Windows 2000 Server CD. If you are unfamiliar with repackaging software, see the "Step-by-Step Guide to Repackaging Software for the Windows Installer Using VERITAS WinINSTALL LE," which explains how to use their repackager.
For more information on this tool, please see the VERITAS Web site http://www.veritas.com.
Best Practice
· You may want to consider natively authoring a Windows Installer package rather than repackaging the application if you have all of the files for an application, if you know the changes that application makes to the registry for installation, and if there are not too many files.
· Success with repackaging is affected by the state of the computer where the repackaging is performed. For best results, you should always start the repackaging of an application with a clean computer. For the purpose of repackaging, a clean computer is defined as a computer that has only the operating system and operating system service packs installed prior to running the VERITAS Discover program.
Other companies will provide their applications with native Windows Installer support. Please contact your favorite application vendors for information on their Windows Installer support plans.
Non-Windows Installer Applications
It is possible to publish applications that do not install with the Windows Installer. They can only be published to users and they are installed using their existing Setup programs.
Because these non-Windows Installer applications use their existing Setup programs, such applications cannot:
· Use elevated privileges for installation.
· Install on the first use of the software.
· Install a feature on the first use of the feature.
· Rollback an unsuccessful operation, such a install, modify, repair, or removal, or take advantage of other features of the Windows Installer.
· Detect a broken state and automatically repair it.
Before an existing Setup program can be used with Software Installation and Maintenance, it must be described in a ZAP (.zap) file, which is a text file, similar to .ini files, which provides the following information:
· How to install the program -- which command line to use.
· The properties of the application -- name, version, language.
· The entry points that the application should automatically install -- for file extension, CLSID, and ProgID.
Note that .zap files are stored in the same location on the network as the Setup program they reference. The appendix contains an example of a .zap file.
Creating a Software Distribution Point for the Windows Installer Applications
To manage software, you must create a software distribution point (SDP) that contains all the Windows Installer packages (.msi files), .zap files, and the actual software files.
To create a software distribution point, you do the following:
· Create a network share along with the appropriate folders for software distribution.
· Copy the Windows Installer packages, application executable files, and .zap files to the appropriate shared folder.
· Set the appropriate permissions for the high-level network shared folder. Users must have the ability to read from the software distribution point. Set the following Discretionary Access Control (DACL) permissions:
Everyone: Read
Administrators: Full Control, Change, and Read.
The following procedure shows you how to set up the distribution point.
To create the software distribution point:
1. Log on to the HQ-RES-DC-01 server as an administrator.
2. Double-click the My Computer icon.
3. Double-click the hard-drive icon of the local disk where you want to create the software distribution point.
4. On the File menu, select New, and then click Folder.
5. Under the New Folder in the selected drive pane, type Managed Applications.
6. Right-click the Managed Applications folder, and select Properties from the context menu.
7. In the Managed Applications Properties page, click the Sharing tab, click Share this folder, and then type Reskit Managed Applications in the Comment text box.
8. Click Permissions. In the Permissions for Managed Applications dialog box, select Everyone, and then under Permissions, clear the Allow permission for the Full Control and Change check boxes. Ensure that Everyone has only Read access to the folder. Click Add.
9. In the Select Users, Computers or Groups dialog box, under Name click Administrators, and then click Add. (Note the Look in text box should be pre-populated with reskit.com.) Click OK.
10. In the Permissions for Managed Applications dialog box, select Administrators, and then under Permissions, set the Full Control and Change permissions to Allow. Ensure that Administrators have Full Control, Change, and Read access to the folder. Click OK.
11. In the Managed Applications Properties dialog box, click OK.
At this point, you should repeat the preceding steps to create any additional folders for the software you are managing. Note that each sub-folder does not need to be explicitly shared or have permissions set. Afterwards, you should copy the Windows Installer packages, .zap files, and the application files to the appropriate shared folders.
You should note that for computer-assigned applications, the network share needs to be reachable by the local system account. This is not the default for Windows NT 4.0 and Novell servers.
Best Practice Administrators should consider using either the distributed file system (Dfs) feature of Windows 2000 Server or Microsoft Systems Management Server to manage their software distribution points.
Top of page
Software Installation Snap-in CONFIGURATION
The Active Directory Users and Computers snap-in is part of the Administrative Tools program group. It already has a Group Policy and Software Installation snap-in. You may either follow these steps to configure your own tool, a saved snap-in, or use the Active Directory Users and Computers snap-in.
Creating a Software Installation Snap-in Tool
To create the Software Installation snap-in:
1. Log on to the HQ-RES-DC-01 server as an administrator.
2. Click Start, click Run, type mmc, and then click OK.
3. In the MMC console, click Add/Remove Snap-in on the Console menu.
4. In the Add/Remove Snap-in dialog box, click Add.
5. In the Add Stand-alone Snap-in dialog box, click Active Directory Users and Computers on the Available Standalone Snap-ins list, and then click Add. Click Close, then click OK.
6. In the console tree, double-click Active Directory Users and Computers to expand the tree, double-click the reskit.com domain, double-click the Accounts organizational unit (OU).
7. Click the + next to the Headquarters OU.
Saving the Software Installation Snap-in Tool
As you go through this guide, you may want to save changes to the MMC console.
To save your changes:
1. In the MMC console, click Save on the Console menu.
2. In the Save dialog box, type SIM Tool in the File name text box, and then click Save.
Your snap-in will look similar to Figure 1 below.

Figure 1: Software Installation Snap-In
Creating a Group Policy Object
If you have already completed the Group Policy step-by-step guide, then you may have already created the necessary Group Policy objects (GPOs).
To create a Group Policy Object (GPO):
1. In the Software Installation snap-in tool you just saved (SIM Tool console), in the console tree, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
2. Right-click Headquarters, and select Properties from the context menu.
3. In the Headquarters Properties dialog box, click the Group Policy tab, and then click New.
4. Type HQ Policy.
This creates a new Group Policy object called HQ Policy.
At this point, you could add another GPO—giving each one that you create a meaningful name—or you could choose to edit a GPO, which starts the Group Policy and Software Installation snap-ins. If you have more than one GPO associated with an Active Directory folder, verify the order; a GPO that is higher in the list is processed first.
5. Click Close.
Best Practice Consider using security descriptors (DACLs) on the GPO to increase the granularity of software management for your organization.
To close the Software Installation snap-in:
1. In the SIM Tool console, click Save on the Console menu.
2. Click Exit on the Console menu.
To edit a Group Policy Object (GPO):
1. Log on to the HQ-RES-DC-01 server as an administrator.
2. Click Start, point to Programs, click Administrative Tools, and then click SIM Tool.
3. In the SIM Tool console, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
4. Right-click Headquarters, and select Properties from the context menu. In the Headquarters Properties dialog box, click the Group Policy tab. Right-click HQ Policy in the Group Policy Object Links list box, and click Edit.
This opens the Group Policy snap-in.
5. In the Group Policy snap-in, under Computer Configuration node, double-click Software Settings.
6. In the console tree, under the User Configuration node, double-click Software Settings.
You have opened the Software Installation snap-in for the HQ Policy GPO. Your snap-in should look like Figure 2 below.

Figure 2: Group Policy Snap-In
You can use the Software Settings node in the console tree under HQ Policy and Computer Configuration to assign an application to computers that are managed by this GPO. You use the Software Settings node under the User Configuration node to assign or publish an application to users who are managed by this GPO.
Configuring the Software Installation Defaults for a Group Policy Object
You can configure default settings for Software Installation on a per-Group Policy Object (GPO) basis.
To specify software installation defaults for the selected Group Policy object, you use the Software Installation Properties dialog box, shown below in Figure 3. This section explains some of the available options.

Figure 3: The Software Installation Properties page
Setting Options for New Packages and Installation User Interface
To control what happens when you add a new package to the selected GPO, you use the General tab in the Software Installation Properties dialog box, and set options in the New packages frame. The default behavior is that the Deploy Software dialog box appears each time, and the administrator can select one of the choices from that dialog box.
If you are going to deploy several packages to a GPO as published without transforms, you can select Publish in the New Packages frame, and every package that is deployed is automatically published. If you are going to add a package with a transform (customization or .mst file), you must select Advanced published or assigned.
Note: You cannot add or change transforms (.mst files) after the software is deployed.
This setting is most useful when an administrator is adding several applications at one time. For example, if an administrator is adding five applications to this GPO and they are all to be published with no transforms, then the administrator could set this to Publish.
Similarly, the options in the Installation user interface options frame allow the administrator to set how much of the user interface (UI) the Windows Installer presents to a user during installation. The Basic UI (the default option) only presents progress bars and messages; no user choices are presented other than Cancel. The Maximum UI option shows the UI that the author of the Windows Installer package defined.
Setting Options for Categories
When an organization has a large amount of software to manage, administrators can create categories for software. These categories can then be used to filter the software in the Add/Remove Programs in Control Panel. For example, you could create a category called Productivity Applications and include software such as word processing and database management applications.
Although there is a Categories tab on the Software installation Properties dialog box, categories are established on a per-domain basis. This means the domain administrator can create and edit the categories from any of the Software installation Properties pages for any GPO in the domain. Administrators can then use these categories with software they are managing within any GPO in the domain. There are no default or supplied categories.
Best Practice Because Categories are established per domain rather than per GPO, an organization should standardize the Categories and create them in a centralized manner.
To configure the default settings:
1. In the Group Policy snap-in console tree, right-click Software installation under User Configuration, and then click Properties. This opens the Software Installation Properties dialog box. You use this dialog box to set defaults for software installation in the current GPO. You can set the default package location to the network location of the software distribution point you created earlier. Then you do not have to browse for each package that you add.
2. In the Software installation Properties dialog box, click Browse.
You need to browse for the software distribution point you created in the previous section relative to the network share location, rather than the local drive on the server. This ensures that you are managing software from the network share location that users can access. Users cannot access the package from the local drive of the server.
3. In the Browse for Folder dialog box, click the plus sign (+) next to My Network Places, double-click Entire Network, double-click Microsoft Windows Network, and then double-click reskit.com.
4. Double-click HQ-RES-DC-01, click Managed Applications, and then click OK.
Note: The exact navigation above may differ on your network. Be sure that you are pointing to the software distribution point relative to the network rather than relative to the local drive on the server.
5. In the Software Installation Properties dialog box, click the General tab, select the Display the Deploy Software dialog box (default) in the New Packages field, and select Basic (default) in the Installation user interface options field.
6. In the Software installation Properties dialog box, click the Categories tab. Click Add.
7. In the Enter new category dialog box, type Productivity Applications in the Category text box, and then click OK. In the Categories tab, click Add.
8. In the Enter new category dialog box, type System Applications in the Category text box, and then click OK. Click OK.
Later, if you want to change these defaults or add additional categories for the organization, you can return to the Software installation Properties dialog box. As mentioned previously, categories are per-domain, not per GPO.
At this point you can either close the Software Installation snap-in or proceed with the scenarios described next.
Top of page
Software Installation and Maintenance Scenarios
Scenarios Covered in this Document
This guide covers a few basic scenarios for Software Installation and Maintenance, including:
· Assigning repackaged Microsoft Word 97 (to users).
· Publishing Microsoft Excel 97 (using a .zap file).
· Removing Excel 97.
· Upgrading Word 97 to Microsoft Office 2000 (using an Office 2000 transform).
· Assigning Windows 2000 to a computer (a new build).
As the packages for these applications are not included, you may have to modify the step-by-step guide. You may use applications that either natively support the Windows Installer or that you have repackaged for the Windows Installer.
Please note that this guide does not describe all of the possible Software Installation and Maintenance scenarios. You should use this guide to gain an understanding of Software Installation and Maintenance. Then think about how your organization might use software installation and the other IntelliMirror features to reduce TCO.
Note: If you completed the Group Policy step-by-step guide, it may be necessary to undo some of the Group Policy to complete this guide. For example, the Loopback policy disables the ability to access the Add/Remove Programs in the Control Panel.
Assigning Repackaged Word
Whether publishing or assigning software, the basic steps are fundamentally the same. This guide presents a scenario for assigning a repackaged version of Microsoft Word 97 for users.
This procedure assumes that you have already created a Word97 folder in the software distribution point created earlier, and that you are using a repackaged version of Microsoft Word 97.
Note: To assign to users, start in the Group Policy snap-in User Configuration node. To assign to computers, start in the Computer Configuration node.
To assign repackaged Word or other software:
1. Log on to the HQ-RES-DC-01 server as an administrator.
2. Click Start, point to Programs, click Administrative Tools, and then click SIM Tool.
3. In the SIM Tool console, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
4. Right-click Headquarters, and select Properties from the context menu. In the Headquarters Properties dialog box, click the Group Policy tab. Right-click HQ Policy in the Group Policy Object Links list box, and click Edit to open the Group Policy snap-in.
5. In the Group Policy snap-in, under User Configuration, double-click Software Settings, right-click Software installation, and then select New from the context menu. Click Package.
6. In the Open dialog box, click the Word97 folder.
7. You need to substitute the folder for the software you are going to deploy, from the software distribution point you created earlier.
8. Click Open. Click Word, and click Open. In the Deploy Software dialog, click Assigned, and then click OK.
Note: If you are going to deploy a Windows Installer package with a transform, you have to select Configure package properties in the Deploy Software dialog so that you can associate the transform with the package. Make any other changes to the properties at this point, before you press OK to either assign or publish the software.
The application is added to the Software Installation snap-in as assigned. After the application is assigned, you can right-click the application entry in the details pane to view the assigned applications property pages.
The application is assigned to all the users managed by the Headquarters GPO.
Verifying the Effect of Assigning Word
To verify the effect of assigning Word 97 to the Headquarters GPO, you can log on to Windows 2000 Professional as a user who is managed by the Headquarters OU. (If you are using the common infrastructure, you could log on to the client as elizabeth@reskit.com, for example.)
When you log on to Windows 2000 Professional, you should see a Microsoft Word icon on the Start menu.
If you select Word, the Windows Installer installs Word for you. While the installation is proceeding, you should see a progress indicator from the Windows Installer. When the installation is complete, Word starts and you can edit a document.
If the software installation becomes damaged, then the next time the user selects Word from the Start menu, if all the key files as defined in the Windows Installer package for Word are present, Word starts. If a key file is missing or damaged, the Windows Installer repairs Word and then starts it.
Publishing Legacy Excel
To publish Excel 97 without repackaging it for the Windows Installer, you must first create a .zap file for Excel. Use the .zap file example in the appendix as a model. You also need to create a folder for Excel97 in the software distribution point you created earlier.
Open the Software Installation snap-in saved previously, and edit the Headquarters GPO. (See the steps in the preceding section.) When you are ready to publish Excel 97, the snap-in should look like it did when you assigned Word 97 in the previous section.
To publish Excel:
1. In the SIM Tool console, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
2. Right-click Headquarters, and click Properties.
3. In the Headquarters Properties dialog box, click the Group Policy tab, click the HQ Policy GPO, and then click Edit to open the Group Policy snap-in.
In the Group Policy snap-in console tree, under User Configuration, double-click Software Settings, right-click Software installation, and then select New from the context menu. Click Package.
4. In the Open dialog box, click the Excel97 folder, and click Open.
In the Files of type combo box, click the down arrow, and then click ZAW Down-level applications package (*.zap). Click Excel97, and click Open.
5. In the Deploy Software dialog box, the Publish option is already selected, click OK.
Excel 97 is published to the users managed by the Headquarters GPO.
Because a ZAP file publishes the existing Setup, the Setup will not run with elevated privileges. Therefore, you will need to supply administrative privileges during the Setup. This can be done by using the Install Program as Other User dialog box. Accessing this dialog is controlled by policy. A policy called Request credentials for network installations is available in the Group Policy snap-in, under User Configuration\Administrative Templates\Windows Components\Windows Explorer. If enabled, this policy displays the Install Program As Other User dialog box even when a program is being installed from files on a network computer across a local area network. For more information, see the Explain tab on this policy property page.
To set the Request Credentials for network installations policy:
1. In the SIM Tool console, navigate to the Headquarters OU, and then right-click Headquarters and click Properties.
2. In the Headquarters Properties dialog box, double-click the HQ Policy GPO to open the Group Policy snap-in.
3. In the Group Policy snap-in, under User Configuration, click the + next to Administrative Templates.
4. In the Request credentials for network installations dialog box, click Enabled, and click OK. Close the Group Policy snap-in
In the Headquarters Properties dialog box, click OK.
5. In the SIM Tool console, click Save on the Console menu. Click Exit on the Console menu.
Verifying the Effects of Publishing Excel 97
To verify the effect of publishing Excel 97 to the Headquarters GPO, first log on to Windows 2000 Professional as a user who is managed by the Headquarters OU. (If you are using the common infrastructure, you could log on as elizabeth@reskit.com, for example.)
To confirm the effects of publishing Excel 97:
1. Click Start, point to Settings, click Control Panel, and then double-click Add/Remove Programs.
2. In the Add/Remove Programs dialog box shown in Figure 4 below, click Add New Programs.
Note: Word 97, which was assigned, is listed in the Add/Remove Programs dialog box. This is so that users can add or remove the assigned program if they need to. Even if a user removes the assigned application, it is available for installation again the next time the user logs on.

Figure 4: Add/Remove Excel 97
3. Select Microsoft Excel 97 from the Add programs from your network list, and click Add.
You should see the Install Program As Other User dialog box shown in Figure 5 below because you are installing a non-Windows Installer based application.

Figure 5: Install Program as Other User
4. In the Install Program As Other User dialog box, click Run the program as the following user, type Administrator in the User Name text box, and type the domain name (reskit) in the Domain box. If you have an Administrator password set for this computer, you must enter this as well.
5. Click OK.
Excel now installs using the original Setup program. You should follow the instructions in the original Setup UI to complete the installation. After you have installed Excel, you can close the application.
6. Close Add/Remove Programs, and then close Control Panel.
7. Log off Windows 2000 Professional.
To remove Excel 97:
1. In the SIM Tool console, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
2. Right-click Headquarters, and click Properties.
3. In the Headquarters Properties dialog box, click the Group Policy tab, click the HQ Policy GPO, and then click Edit to open the Group Policy snap-in.
4. In the details pane, right-click Microsoft Excel 97, and select All Tasks from the context menu.
5. Click Remove.
6. In the Remove Package dialog box, click Yes.
Note: Because Excel 97 was installed using a .zap file, you do not have the option to force the removal as you would with a Windows Installer file.
Microsoft Excel 97 no longer appears in the details pane.
7. Log on to the Windows 2000 Professional as the Local Administrator (remember, Excel was installed as Administrator in the preceding scenario).
8. Click Start, point to Settings, click Control Panel, and then double-click Add/Remove Programs.
9. In the Add/Remove Programs dialog box, click the Microsoft Excel 97 entry in the Change or Remove Programs frame, and then click Change/Remove.
10. The Excel 97 Setup program starts. In the Microsoft Excel 97 Setup dialog box, click Remove All.
11. When Setup prompts you about removing Microsoft Excel 97, click Yes. Click OK.
12. Close Add/Remove Programs, and then close Control Panel. Log off Windows 2000 Professional.
Upgrade Microsoft Word 97 to Office 2000 With a Transform
Office 2000 comes with a Windows Installer package natively authored. Before performing this upgrade, use the Office 2000 Customization Wizard to create a transform. You must substitute the name of your transform in this scenario.
This procedure assumes that you have placed the necessary files (.msi, .mst, and so on) in a folder called Office in the software distribution point.
To upgrade Word 97 to Office 2000
1. In the SIM Tool console, double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Accounts.
2. Right-click Headquarters, and click Properties.
3. In the Headquarters Properties dialog box, click the Group Policy tab, click the HQ Policy GPO, and then click Edit to open the Group Policy snap-in.
4. In the Group Policy snap-in, under User Configuration, double-click Software Settings, right-click Software installation, click New, and then click Package.
5. In the Open dialog box, click the Office folder, and click Open. Select the Office 2000 Windows Installer package (data1.msi), and click Open.
6. In the Deploy Software dialog box, click Advanced published or assigned, and click OK.
7. In the Microsoft Office 2000 Properties dialog box, click the Modifications tab, and click Add.
8. In the Open dialog box, click Office, and then click Open. Select the Office 2000 transform (.mst), and click Open.
Note: It is important that you do not click OK until you have set all the options for the modifications.
9. In the Microsoft Office 2000 Properties dialog box, click the Upgrades tab, and click Add.
10. In the Add Upgrade Package dialog box, Microsoft Word 97 should be highlighted in the Package to Upgrade list box. If not, click it to select it. Click Uninstall the existing package, then install the upgrade package, and then click OK.
11. In the Microsoft Office 2000 Properties dialog box, click the Required Upgrade for existing packages checkbox. Do not click OK yet.
12. In the Microsoft Office 2000 Properties dialog box, click the Deployment tab, click Assigned in the Deployment type field, and accept the default option (Basic) in the Installation user interface options field.
Review all the tabs to make sure you have edited all the properties and you are ready to assign the upgrade. Click OK.
Office 2000 with the transform is added to the Software Installation snap-in. The snap-in should now show Office 2000 as assigned, and it should show an upgrade relationship between Word 97 and Office 2000.
At this point, if you log on to Windows 2000 as a user in the HQ Policy GPO, you should see Word 97 being removed, the start of the upgrade. When you select any of the Office icons from the Start menu, you install Office 2000 to complete the upgrade.
Assigning Windows 2000 to a Computer Upgrading Windows 2000
You can upgrade Windows 2000 to the release version.
Note: The operating system build being upgraded must be older than the build you are upgrading to.
If you completed the Group Policy guide before this, you may have turned off applying Group Policy to computers. If this is the case, you need to change this before this Software Installation policy can be applied on the computers.
In this scenario, you assign the upgrade of Windows 2000 to computers managed by a policy created for the Desktops OU under Resources. You could just as easily publish it for users.
The RES-WKS-01 computer should be in the Desktops OU. If it is not, you need to move it to one of the OUs under the Resources OU. You can move the computer by highlighting it in the details pane of the Active Directory Users and Computers Snap-in and then selecting Move from the context menu.
Note: To deploy the Winnt32.msi package, you need to modify the Unattend.txt file to include the Windows 2000 CD key information. Otherwise, the Setup program would ask for this information in a non-interactive desktop and wait indefinitely.
1. Open the SIM Tool console you created earlier.
2. Double-click Active Directory Users and Computers, double-click reskit.com, and then double-click Resources.
3. Right-click Desktops, and click Properties.
4. Click the Group Policy tab, click New, and type Desktop OS Upgrades. Press Enter. Click Edit.
5. In the Group Policy snap-in, under Computer Configuration, double-click Software Settings.
6. Right-click Software installation, click New, and then click Package.
7. Browse to the network to the software distribution point that has the Windows 2000 files.
Note: You may want to place the Windows 2000 CD in the CD drive of the server, and share the CD-ROM drive as the software distribution point for these files. This saves having to copy all the files to the software distribution point, although if the CD-ROM drive is not fast, the install may take longer.
8. Click the i386 folder, click Open, click WINNT32 (.msi file), and then click Open.
9. In the Deploy Software dialog box, the Assigned option on the Deploy Software dialog box is already selected. Click OK.
10. Close the Group Policy snap-in, then in the Desktop Properties dialog box, click Close in the Group Policy page.
11. In the SIM Tool console, click Save on the Console menu, and then click Exit on the Console menu.
At this point you should restart the RES-WKS-01 computer. When you do, the normal shutdown and startup messages are displayed.
Eventually, in the Windows 2000 Professional startup dialogs you should see the following messages:
Applying Software Installation settings…
Followed by:
Windows Installer installing managed software Windows 2000 Professional…
The computer restarts and continues the upgrade.
Important Notes
The example company, organization, products, people, and events depicted in these guides are fictitious. No association with any real company, organization, product, person, or event is intended or should be inferred.
This common infrastructure is designed for use on a private network. The fictitious company name and DNS name used in the common infrastructure are not registered for use on the Internet. Please do not use this name on a public network or Internet.
The Microsoft Active Directory™ structure for this common infrastructure is designed to show how Microsoft Windows 2000 Change and Configuration Management works and functions with the Active Directory. It was not designed as a model for configuring an Active Directory for any organization—for such information see the Active Directory documentation.